Deep ViT Features as Dense Visual Descriptors
Supplementary Material
Scroll down to observe results. Further results and information appear in links above. Click on an image to see it in full resolution.
Pair Part Co-segmentation
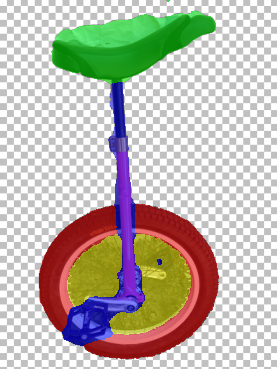
We apply our part co-segmentation method in an extreme setting - given a only a pair of images with varations in pose, scale, appearance, quantity and background clutter. (See Fig. 6).
 |
 |
 |
 |
|---|
 |
 |
 |
 |
|---|
 |
 |
 |
 |
|---|
 |
 |
 |
 |
|---|
 |
 |
 |
 |
|---|
.JPG) |
 |
_crf_overlay_checkerboard_3.png) |
 |
|---|
 |
 |
 |
 |
|---|
 |
 |
 |
 |
|---|
 |
 |
.png) |
.png) |
|---|
 |
 |
 |
 |
|---|
 |
 |
 |
 |
|---|
 |
 |
 |
 |
|---|
_resized.png) |
 |
_vis - Copy.png) |
.png) |
|---|
 |
 |
 |
 |
|---|
 |
.jpg) |
 |
_crf_overlay_checkerboard_3.png) |
|---|
 |
 |
.png) |
.png) |
|---|
 |
 |
.png) |
.png) |
|---|
 |
_front_MJ.JPG) |
 |
_front_MJ_crf_overlay_checkerboard_3.png) |
|---|
Video Part Segmentation
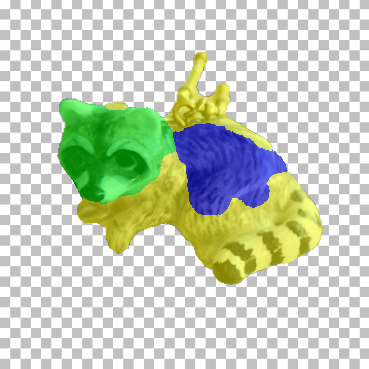
We apply our part co-segmentation method (Sec. 5.1 in paper) to video frames — we treat the frames from each video as a collection of images, and apply our method without any changes. No temporal information is used. Notice the consistency of object parts through time under large motion varaitions and occlusions in DAVIS and in camouflaged examples in MoCA.
MoCA examples
| Original Video | Part Co-segmentation |
|---|---|
DAVIS examples
| Original Video | Part Co-segmentation |
|---|---|
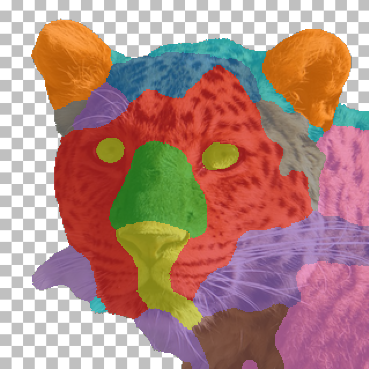
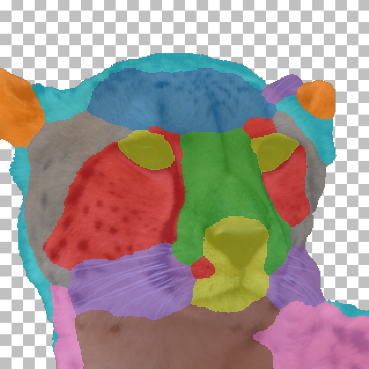
AFHQ Results
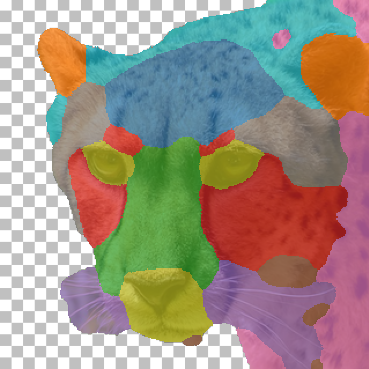
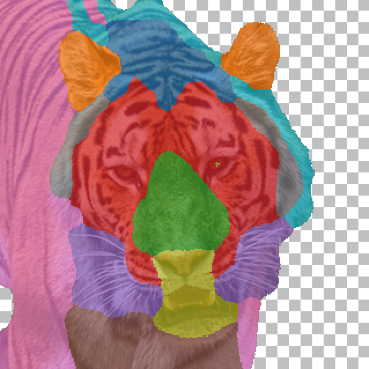
Randomly chosen part co-segmentation results on the AFHQ test set (see Fig. 7). Our method produces consistent parts across different animals with difference in appearance and pose. (e.g. the method chose to separate: ears, forehead, muzzle, around the eyes, whiskers, chest, torso, temples, eyes, nose and mouth, hairline).
| Original | Our Result | Original | Our Result | Original | Our Result | ||
|---|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
||
| Original | Our Result | Original | Our Result | Original | Our Result | ||
 |
 |
 |
 |
 |
 |
CUB Comparison
We apply our part co-segmentation on CUB test set (Sec. 5.1, Fig. 8). We compare to the recent SOTA part-segmentation methods SCOPS [1] and Choudhury et al. [2], both of were trained on CUB specifically for this task, using ground-truth foreground/background masks.
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
| Original | SCOPS | Choudhury et al. | Ours |
|---|---|---|---|
 |
 |
 |
 |
References
[1] Unsupervised Part Discovery from Contrastive Reconstruction. Choudhury et al. NeurIPS 2021
[2] SCOPS: Self-Supervised Co-Part Segmentation Hung et al. CVPR 2019
Sparse Correspondences
We apply our sparse correspondences algorithm on several examples (see Fig. 10), and compare to NBB [1]. Our method is more robust to changes in pose, scale, appearance and non-rigid deformations.
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|
| NBB | Ours | |||
|---|---|---|---|---|
 |
 |
 |
 |
|